| What is AVS2 | AVS Milestones | AVS2 Coding Tools | AVS2 Download |
|
| What is AVS2 | AVS Milestones | AVS2 Coding Tools | AVS2 Download | |
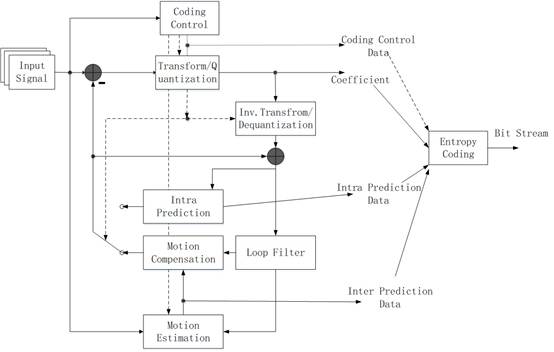
AVS2 Coding ToolsAVS2 adopts a hybrid-coding framework, and the whole coding process includes modules such as intra-frame prediction, inter-frame prediction, transformation, quantization, inverse quantization and inverse transformation, loop filter and entropy coding. It owns technical features as followings:
1. Flexible Coding Structure PartitionIn order to satisfy the requirements of HD and Ultra HD resolution videos for the compression efficiency, AVS2 adopts a block partition structure based on the quadtree, including the CU (Coding Unit), PU (Prediction Unit) and TU (Transform Unit). An image is partitioned into LCU (Largest CU) of fixed size, which is iterated and partitioned into a series of CUs in the form of quadtree. Each CU contains a luminance-coding block and two corresponding chrominance-coding blocks (the size of the block unit below refers to the luminance coding block). Compared with the traditional macro block, the partition structure based on the quadtree is more flexible, with the CU size extended from 8×8 to 64×64.
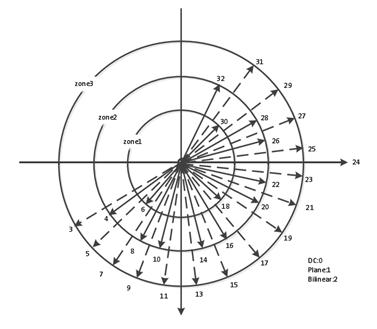
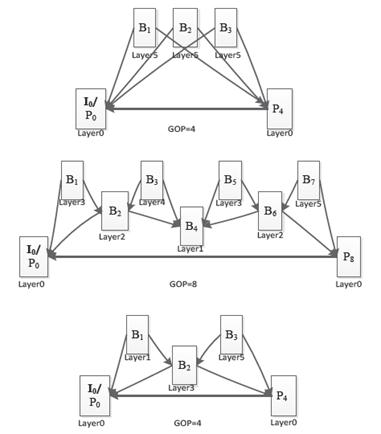
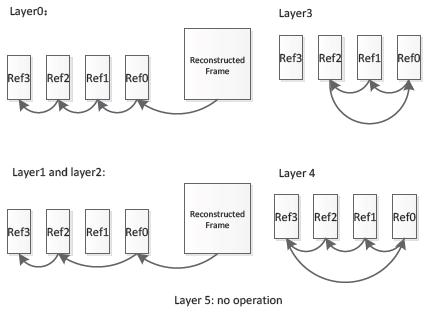
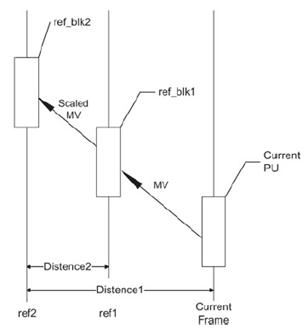
The PU stipulates all prediction modes of CU, and it is the basic unit for the prediction, including intra-frame and inter-frame prediction. The maximum size of PU is not permitted to exceed that of the current CU it belongs to. On the basis of AVS1 square intra-frame prediction blocks, the non-square intra-frame prediction block partition is added. Meanwhile, on the basis of the symmetric prediction block partition, the inter-frame prediction also adds 4 asymmetric partition ways. Besides CU and PU, AVS2 also defines a transformation unit TU for the prediction of residual transformation and quantization. TU is the basic unit of transformation and quantization, defined in CU like PU. Its size selection is related to the corresponding PU shape. If the current CU is partitioned into non-square PU, the non-square partition will be applied to the corresponding TU; otherwise, the square partition type will be applied. It should be noted that the size of TU could be greater than that of the PU, but no more than that of the CU it belongs to. 2. Intra PredictionCompared with the AVS1 and H.264/AVC, AVS2 designs 33 modes for the intra-frame prediction coding of luminance blocks, including DC prediction mode, plane prediction mode, bilinear prediction mode and 30 angel prediction modes. There are 5 modes for chrominance blocks: DC mode, horizontal prediction mode, vertical prediction mode, bilinear interpolation mode as well as the luminance derived mode (DM) newly added. 3. Inter Prediction3.1 Reference Frame ManagementCompared with AVS1, AVS2 increases the maximum quantity of candidate reference frames to 4, so as to adapt to the multi-level reference frame management, which also takes full advantage of the redundant space of the buffer. In order to satisfy the requirements of multiple reference frame management, AVS2 adopts a kind of multi-level reference frame management mode. In this mode, the frames in each GOP (Group of Pictures) are partitioned into multiple levels according to the reference relationship between frames.
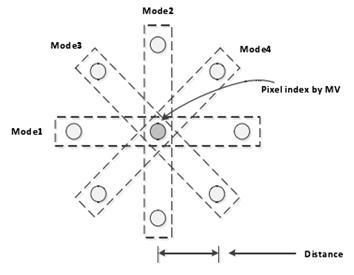
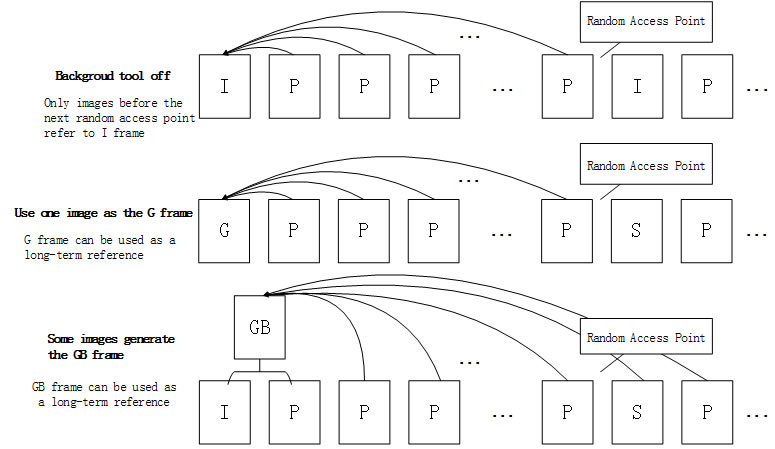
3.2 Inter Prediction ModeOn the basis of AVS1’s three image types I, P, B, according to the requirements of application, AVS2 adds the forward multi-hypothesis prediction image F. Aiming at the video surveillance, scene play and other specific applications, AVS2 designs scene frames (Image G and Image GB) and reference scene frame S. For Frame B, in addition to traditional forward, backward, two-way mode and skip/direct mode, a new symmetric mode is added. In symmetric mode, only forward motion vectors are required to be encoded, and then backward motion vectors will be derived from the forward motion vectors. In order to fully exert the performance of the skip/direct mode of Frame B, AVS2 also adopts multi-direction skip/direct mode under the premise of retaining the original skip/direct mode of Frame B: two-way skip/direct mode, symmetrical skip/direct mode, backward skip/direct mode and forward skip/direct mode. For the four particular modes, the same prediction mode block between adjacent blocks is discovered according to the prediction mode of the current block, and the motion vectors of adjacent blocks with the same prediction mode, which are found out first, will be considered as that of the current block. The scene frame is proposed by AVS2 based on the surveillance video coding method of background modeling. When the surveillance tool is not opened, Frame I is only for reference for images before the next random access point. When the surveillance tool is opened, AVS2 will apply a certain frame in the video as the scene image frame G, which can be considered as a long-term reference for the subsequent images. Besides, AVS2 can generate the scene image frame GB with some frames in the video, and frame GB can also be applied as a long-term reference.
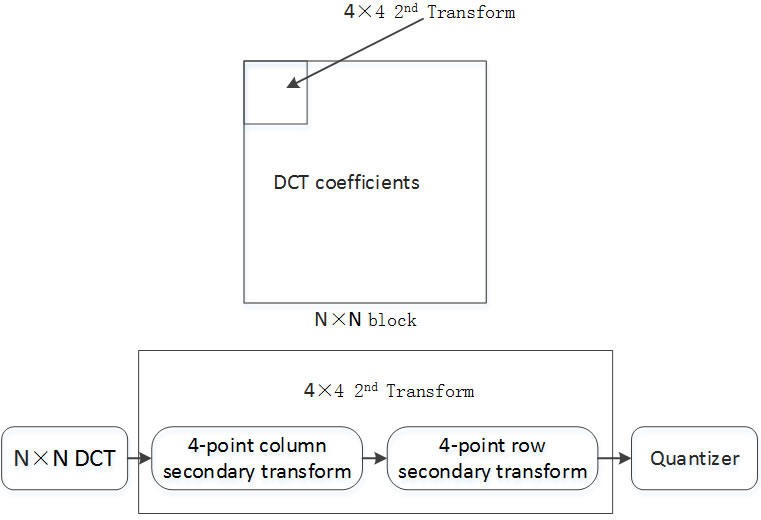
3.3 Interpolation FilteringIn order to simplify the motion compensation, AVS2 adopts an 8-tap interpolation filter based on DCT transformation, which requires only one filtering, and supports the generation of higher motion vector accuracy than 1/4 pixel. 4. TransformationTransformation coding in AVS2 mainly applies integer DCT transformation, which is directly performed on the transformation blocks of Size 4×4, 8×8, 16×16, 32x32. For one transformation block with dimension greater than 64, a logical transformation LOT is adopted to conduct the wavelet transformation, followed by the integer DCT transformation. After the DCT transformation is achieved, AVS2 will conduct the second 4 x 4 transformation for the 4 x 4 blocks with low frequency coefficients, thus further to reduce the correlation between coefficients, and enable the energy to be more concentrated.
5. Entropy CodingThe AVS2 entropy coding divides transformation coefficients into CGs (Coefficient Group) of 4 x 4 size first, and then conducts encoding and zigzag scan according to the CGs. Coefficient coding encodes the CG position containing the last non-zero coefficient first, and then encodes each CG, until all CG coefficients are completed, so as to enable zero coefficients to be more concentrated during the encoding process. Binary arithmetic coding and two-dimensional variable-length coding based on the context are still applied in the AVS2. 6. Loop FilterLoop filter modules of AVS2 contain three parts: deblocking filter, adaptive sample point offset and sample compensation filter. The filtering blocks of the deblocking filter are of an 8×8 size, which conduct filtering on the vertical edge first, followed by the horizontal edge. And diverse filtering methods are selected for each edge according to different filtering intensities. After the deblocking filter, the adaptive sample offset compensation is adopted to further reduce the distortion. The AVS2 adds an adaptive filter after the deblocking filter and sample offset compensation, a Wiener filter with 7×7 cross plus 3×3 square centrosymmetry, which applies the original undistorted image and encoding reconstructed image to figure out the least square filter coefficient, and conduct filtering on the decoding reconstructed image, thus to reduce the compression distortion in the decoding image, and enhance the quality of the reference image. |
| Copyright ©2003-2026 Audio Video Coding Standard Workgroup of China 京ICP备05002832号 |